Naive Bayes Classifier Tutorial
What is Naive Bayes classifier?
Naive Bayes Classifier is a classification technique based on Bayes’ Theorem. It is base on the principle that the predictors are independent of each other. In simple words, we can say that the Naive Bayes classifier assumes that the presence of a particular feature in a class is independent(Unrelated) with the presence of any other feature in the same class. Let's understand this concept by an example, suppose a fruit may be considered to be an orange if it is orange in color, approximately round, and about 2.5 inches in diameter. Here we can see that all of these properties independently contribute to the probability that this fruit is orange, even if these features depend on each other. This is the reason, why it is known as ‘Naive’. (Naive meaning: Unaffected).
Naive Bayes algorithm is simple to understand and easy to build. It do not contain any complicated iterative parameter estimation. We can use naive bayes classifier in small data set as well as with the large data set that may be highly sophisticated classification.
Naive Bayes classifier is based on the Bayes theorem of probability. Bayes theorem can used for calculating posterior probability P(y|X) from P(y), P(X) and P(X|y). The mathematical equation for Bayes Theorem is,
From the equation, we have,
Naive Bayes classifier is based on the Bayes theorem of probability. Bayes theorem can used for calculating posterior probability P(y|X) from P(y), P(X) and P(X|y). The mathematical equation for Bayes Theorem is,
 |
| Mathematical equation of Bayes Theorem |
- X is the feature vector represented as,

feature vector - P(y|X) is the posterior probability (A posterior probability, in Bayesian statistics, is the revised or updated probability of an event occurring after taking into consideration new information ~ Investopedia) of class (y, target) given predictor (X, attributes).
- P(y) is the prior probability(probability as assessed before making reference to certain relevant observations) class.
- P(X|y) is the probability(Likelihood) of predictor given class.
- P(X) is the prior probability of predictor.
Since Naive Bayes classifier assumes the independence of predictors (features), so for independent features, we calculate the output probability using Bayes theorem as,
Which can be represented as,
| Independent Probability |
 |
| Independent Probability |
Since the denominator is constant, we can write,
Now, To create a Naive Bayes classifier model, we find the probability of given set of inputs for all possible values of the class variable y and pick up the output with maximum probability. This can be expressed mathematically as:
| Max probability |
So, finally, we are left with the task of calculating P(y) and P(xi | y).
NOTE: P(y) is also called class probability and P(xi | y) is called conditional probability.
How Naive Bayes classifier works?
Let’s understand the working and algorithm of Naive Bayes Classifier using an example. Below is the training data set for playing golf under different circumstances. We have different features as Outlook, Temperature,Humidity, Windy and we are given label as play golf under different situations of those features. We need to predict whether to play or not for new test data(that we provide) by using naive bayes classification algorithm. Let’s do it step by step and learn this algorithm.
OUTLOOK | TEMPERATURE | HUMIDITY | WINDY | PLAY GOLF | ||
0 | Rainy | Hot | High | False | No | |
1 | Rainy | Hot | High | True | No | |
2 | Overcast | Hot | High | False | Yes | |
3 | Sunny | Mild | High | False | Yes | |
4 | Sunny | Cool | Normal | False | Yes | |
5 | Sunny | Cool | Normal | True | No | |
6 | Overcast | Cool | Normal | True | Yes | |
7 | Rainy | Mild | High | False | No | |
8 | Rainy | Cool | Normal | False | Yes | |
9 | Sunny | Mild | Normal | False | Yes | |
10 | Rainy | Mild | Normal | True | Yes | |
11 | Overcast | Mild | High | True | Yes | |
12 | Overcast | Hot | Normal | False | Yes | |
13 | Sunny | Mild | High | True | No |
Here, The attributes are : Outlook, Windy, Temperature and humidity. And the class (or Target) is Play Golf.
Step 1: Convert the given training data set into a frequency table
Step 2: Create Likelihood table (or you can say a probability table) by finding the probabilities.
 |
| Calculation Table |
In those tables we have calculated both P(y) (i.e. P(yes) and P(no)) and P(xi | y) (e.g. p(humidity,high|yes)).
Step 3: Now, apply Naive Bayesian equation to calculate the posterior probability for each class. The class with the highest posterior probability will be the outcome of prediction.
Step 3: Now, apply Naive Bayesian equation to calculate the posterior probability for each class. The class with the highest posterior probability will be the outcome of prediction.
Lets Suppose our test data be, test = (Sunny, Hot, Normal, False). For this we need to predict whether it will be okay to play golf or not.
Let's Calculate:
Probability of playing golf:
 Probability of not playing golf:
Probability of not playing golf:
 Here, we can see that in both of the probabilities there is a common factor p(test), so we can ignore it. Thus we get the calculation as follows,
Here, we can see that in both of the probabilities there is a common factor p(test), so we can ignore it. Thus we get the calculation as follows,

and,

To convert these numbers into actual probabilities, we normalize them as follows,
 and,
and,
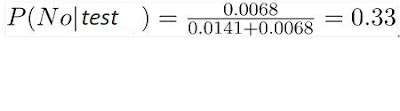 From above calculations, we see that
From above calculations, we see that

Thus, prediction for golf played is 'Yes'.
Let's Calculate:
Probability of playing golf:

and,
To convert these numbers into actual probabilities, we normalize them as follows,


Thus, prediction for golf played is 'Yes'.
What are the Pros and Cons of Naive Bayes Classifier?
Pros:- Naive Bayes Classifier is simple to understand, easy and fast to predict class of test data set.
- It perform quite well in multi class prediction.
- It perform well in case of categorical input variables compared to numerical variable(s).
Cons:
- The model will assign a 0 (zero) probability and will be unable to make a prediction, If categorical variable has a category (in test data set), which was not present in training data set. This type of error is often known as “Zero Frequency”.
- Another limitation with the Naive Bayes is the assumption of independence . In real life, it is almost impossible that we get a set of predictors which are completely independent to each other.
Applications of Naive Bayes Classifier
- Real time Prediction: Naive Bayes Classifier is an eager (not a lazy learner) learning classifier and it is sure fast. Therefore, it could be used for making real time predictions.
- Multi class Prediction: This algorithm is also well known for multi class prediction feature. Here we can predict the probability of multiple classes of target variable.
- Text classification/ Spam Filtering/ Sentiment Analysis: Naive Bayes classifiers widely used in text classification due to better result in multi class problems and independence rule.It have higher success rate as compared to other algorithms. As a result, it is widely used in Spam filtering (identification between ham and spam e-mail) and Sentiment Analysis (in social media analysis, to identify positive and negative sentiments in comments and review)
Comments
Post a Comment