What is Data Pre-Processing? What is the importance of data pre-processing?
The real-world data are susceptible to high noise, contains missing values and a lot of vague information, and is of large size. These factors cause degradation of quality of data. And if the data is of low quality, then the result obtained after the mining or modeling of data is also of low quality. So, before mining or modeling the data, it must be passed through the series of quality upgrading techniques called data pre-processing. Thus, data pre-processing can be defined as the process of applying various techniques over the raw data (or low quality data) in order to make it suitable for processing purposes (i.e. mining or modeling).
What are the various Data Pre-Processing Techniques?
 |
| Fig: Methods of Data Pre-Processing source: Fotolia |
Once we know what data pre-processing actually does, the question might arise how is data processing done? Or how it all happens? The answer is obvious; there are series of techniques and algorithms to perform this task. We can choose any of the techniques depending upon our requirement and feasibility. Some of the most common techniques that are almost used in every situation and we will be dealing about in this article are: Data Cleaning, Data Merging or Data Integration, Data Reduction, Data Transformation.
Let’s discuss each topic individually:
· Data Cleaning
Let’s first understand what is data cleaning? As the name suggests, data cleaning is the process of cleaning the data. Here cleaning refers to the filling of missing, removing noise and outliers. In most of the cases this is the first step of data pre-processing. Generally, data cleaning includes:
a) Handling(Filling) missing values: The missing values in data can be filled using any of the techniques mentioned below:
i. Ignoring/Dropping: In some of the cases it is better to ignore or drop a tuple that contains missing value rather than filling it. Generally this is practiced in large dataset, where excluding some tuples does not affect the information conveyed by the data. But it is discouraged for small dataset as it might lead to losing of important information.
ii. Fill Missing values manually: You can also fill the missing values manually by understanding the nature of data. Usually, this is performed in small dataset rather than large dataset as it is more time consuming in case of large dataset.
iii. Filling Central values (Mean/Median) in missing values: This technique is far better than the above mentioned ones. In these techniques we insert the mean or median of respective attribute to the missing values. For better results first we group the data on the basic of similarities of attributes and apply this technique.
iv. Interpolation: This is one of the reliable, accurate and scientific ways of filling missing value. According to interpolation technique, we first develop relation among the attributes and then predict the most probable and accurate value for the missing places. This can be achieved by regression, Bayesian formulation, and Decision tree induction.
b) Removing Noise (smoothing) from Data: What is noise in data? Actually, noise in data is any kind of random error or variance in measured attributes. The outliers present in data can also be regarded as the noise. The noise present in data may highly affect our mining result (or we can say prediction). So noisy in data is not considered as good data for mining purpose and it should be removed as far as possible. Before we remove noise let’s know how can we detect noise in our data? There are many noise detecting techniques that we can use, but the most scientific and informative technique is visualization technique. It includes visualization of different attributes of data in the form of graph or plots. Some of the informative plots includes scatter plot, box plot etc.
One of the most popular methods used for smoothing (Noise removing) our data is Binning method. This method is used to smooth the sorted value by looking its neighborhoods. The sorted values are distributed into number of bins (groups or buckets). This is also called as local smoothing as it consults neighbor for noise removing.
Let’s see what actually binning means from an example.
We have sorted data as – 7, 9,14,15,17,19,22,25
Bin 1 = 7, 9, 14, 15
Bin 2 = 17, 19, 22, 25
Smoothing by Bin means:We replace each members of bin by the mean of respective bins. It can be shown as:
Bin 1 = 11.25, 11.25, 11.25, 11.25
Bin 2 = 20.75, 20.75, 20.75, 20.75
Smoothing by Bin boundary: We replace the values with nearest boundary value of bin. It can be shown as:
Bin 1 = 7, 7, 15, 15
Bin 2 = 17, 17, 25, 25
Smoothing can also be done by the removing outliers. When similar values are clustered (grouped) then the values that remain outside the cluster are called outliers.
· Data Merging or Data Integration
When dealing with real world data, we might not find all the required data in single dataset. In that case, we need to collect data from different sources and merge them in single dataset and this process of merging or integrating data collected from different source is called data merging or data integration.
While doing data merging, we encounter most common issue called redundancy. Redundancy can be detected by doing correlation analysis. For nominal data (e.g. name of people) we use chi-squared test. For numerical data we can use correlation coefficient and co variance test.
· Data Reduction
Data reduction is defined as the process of reducing data by adopting some strategies in such a way that the analysis of reduced data produces the same information as produced by the original data.
Some of the data reduction strategies include:
- Principal Component Analysis
- Attribute subset selection (Similar principle as in Random tree formation i.e. we make different subsets from original data)
- . Parametric data reduction for Regression and log-linear model.
- Clustering and Sampling
· Data Transformation
In this process, we try to change the nature of data using some strategies, so that we can extract important information from them.
Some of the techniques for data transformation are:
i. Aggregation: In this technique the summary or aggregation operation is applied over the data. E.g. the daily sales data may be aggregated so as to compute monthly and annual amount.
ii. Discretization: In this technique, we construct and replace raw values of a numeric attribute (e.g. age data) by interval values (e.g. 0-10, 10-20, 20-40) or by conceptual values (e.g. child, young, adult).
iii. Attribute construction/ Feature engineering: First let’s understand what feature engineering is? Actually feature engineering is process of constructing/engineering new attribute/feature by observing the available features and relation between them. This technique is helpful in generating extra information from vague data. This technique can be helpful if we have fewer features but still they contain hidden information to extract.
iv. Normalization/Standardization: What is Normalization or Standardization? Normalization or standardization is defined as the process of rescaling original data without changing its behavior or nature. We define new boundary (mostly 0,1) and convert data accordingly. This technique is useful in classification algorithms involving neural network or distance based algorithm (e.g. KNN, K-means).
Why is normalization important?
Let’s understand it by an example. Suppose we are making some predictive model using dataset that contains the net worth of citizens of any country. For this dataset we find that there is large variation in data. If we feed this data to train any model, then it may generate some undesirable results. So, to get rid of that we opt normalization.
Some normalization techniques are:
a) Min-Max Normalization: Let (X1,X2) be min and max boundary of an attribute and (Y1,Y2) be the new scale at which we are normalizing, then for Vi value of attribute, the normalized value Uiis given as,
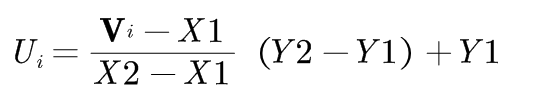
b) Z-score Normalization(Zero mean normalization): For Vi value of attribute A, normalized value Uiis given as,

c) Decimal Normalization:If Vi value of attribute A, then normalized value Uiis given as,

Where, j is the smallest integer such that max|Ui|<1.
I have written this article taking reference of book DATA MINING Concepts and techniques by Jiawei Han, Micheline Kamber, and Jian Pei. You can download this book free here
Nice one. Helped me clear concepts. But has some typos. Better fix them.
ReplyDeleteThanks For the suggestions and comments.
ReplyDeleteNailed it Man!!
ReplyDelete